
我々がコンピューターに要求するのは、いったいなんでしょうか? 自分のことばを正確に理解してくれることでしょうか? 承認要求の非常に高い人たちの中には、そういう方もいらっしゃるかもしれません。
しかし、ふつうに暮らしている人々がコンピューターに求めるのは正確に問題を解決する能力でしょう。その点で生成AIはみごとなほど落第点しか取れない機械です。その実情の悲惨さは、次の2段組グラフの上段にはっきり出ています。
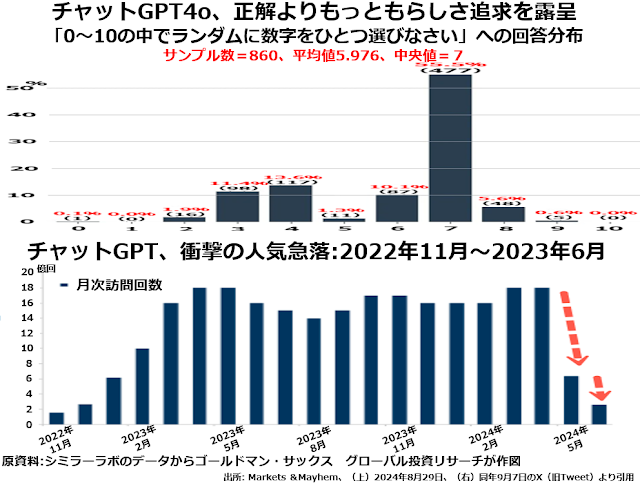
「0から10までの11個の数字の中から、無作為抽出で数字ひとつを決めなさい」というこれ以上シンプルな質問はなかろうという質問に860回答えた結果の分布図です。
もちろん、無作為抽出ということばの意味を理解していれば、サンプル数が大きくなるほど解答は11分の1ずつ、つまり約9%が均等に並ぶはずです。
ところがチャットGPT-4oは、4年制大学卒もふくめてアメリカの成人男女の平均的な数学的素養が日本の高校受験生よりはるかに低いという事実をそっくりなぞって「どんな数字なら、でたらめに選んだ数字に見えるか」という答えを出してしまったのです。
つまりラージランゲージ・モデルを使った生成AIの数学問題への取り組み方は、数学問題の正解は数学自体が教える論理的帰結としてではなく、世論調査で決めようということなのです。これはもう、直しようのない致命的欠陥と言えるでしょう。
こうしたお寒い現状を反映して、チャットGPT歴代モデルに月間で何回訪問があったかというデータが、2024年5~6月で急落しました。下段のグラフが示すとおりです。
2023年4~5月の18億回弱がピークでなかなかそのピークを抜けなかったのですが、今年3~4月にもう一度過去最大回数に挑戦した直後の5月には一挙に約6億回に激減し、さらに6月には辛うじて2億回を上回る水準まで低下しています。
さらに次の2段組グラフの上段は、もし生成AIが実用に堪えるものであったとすればかなり大きな恩恵を受けるはずの情報産業の収益性が、2009~10年の国際金融危機からの急反発をピークに延々と低下しつづけてきたことを示しています。







































