
FULL KAITENはどんなデータを分析しているか
ここまでで、市場縮小・予測偏重・組織の部分最適・誤ったデータ分析という4つが在庫問題を複雑化しているという話をしました。
最後に少しだけ、当社が提供している「FULL KAITEN」について触れてみたいと思います。
FULL KAITENが在庫分析のためにインプットしているデータの一例は以下の通りです。
- 商品マスタ
- 店舗マスタ
- 売上データ
- 在庫データ
これらを導入店舗ごとや商品カテゴリーごとに切り分けるなどし、店舗ごとあるいはカテゴリーごとの年間の売れ方や年間を通じた季節ごとの売れ方の特徴を数値化し、未来の予測に反映しています。
FULL KAITENがアウトプットする未来の予測値の一例を挙げます。前章で述べた「完売予測日数(週数)」と「売上・利益貢献度」という2軸の予測値で全商品の在庫リスクを可視化しています。
具体的には、下図のように「この先何月何日までに売り切れるか?(X軸)」「この先どれ程の売上を生むか?(Y軸)」という2つの軸で在庫一つひとつを評価し、店舗(実店舗・EC)ごとに在庫の「質」を可視化します。
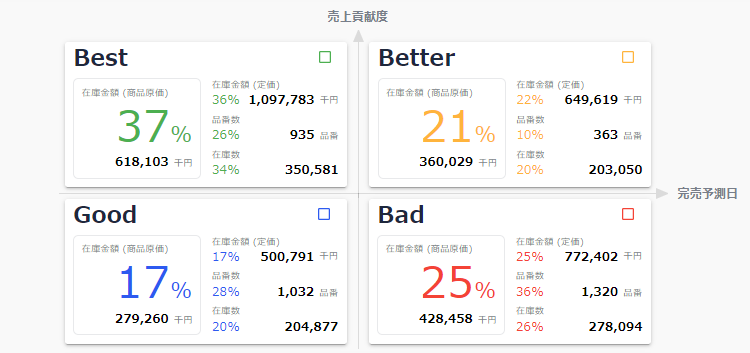 右上のBetterに分類された在庫は、完売するまでに時間を要するものの、売上に対する貢献度は高い商品です。Bestのような売れ筋商品にばかり拘っていると、Betterのような隠れた売れ筋商品の存在に気づけません。
右上のBetterに分類された在庫は、完売するまでに時間を要するものの、売上に対する貢献度は高い商品です。Bestのような売れ筋商品にばかり拘っていると、Betterのような隠れた売れ筋商品の存在に気づけません。
実はこれはほぼ全ての企業で起こっています。Betterの存在に気づけずに販売機会を失っているから、値引きが多くなってしまうのです。
冒頭紹介した「残り80%の在庫」の多くはBetterに含まれているので、これらの存在をタイムリーに把握して在庫リスクが悪化する前に販促をできるだけ値引きを抑えて優先的に行うことによって、いま手元にある在庫からこれまで失っていた利益を確保しつつ売上を立てていくことができます。
つまり利益の機会損失を抑制できるということです。私たちはこれを「在庫の運用効率を上げる」という言い方をしています。
膨大なデータをクラウドに連携する際の苦労
当社ではデータ連携を行う専門チームがありますが、専門チームといえども、お客様のデータ構造を把握しデータ連携していく作業には苦労します。しかし、これは大きなやりがいを感じるプロセスでもあります。
今まで様々なお客様のデータを拝見しましたが、面白いことに同じ業種であっても商品マスタが同じ構造というお客様はいません。これは、各企業で管理したい情報が異なるためですが、商品マスタ構造の業界標準が存在しないこともデータ分析力が育たない一因だと私は思っています。
例えば商品を管理する品番体系1つをとっても、品番の上位何桁がカラーコードで、 下位何桁はサイズコードという組み合わせで1つの品番になっているケースと、カラーコード、サイズコードを分けて管理している会社もあります。
このように、各社のデータ仕様が統一されていないという事情が、分析手法の統一が業界全体でなされにくいという風土を生んでしまっていると感じています。
もし各社のデータ仕様が統一されていれば、うまくいっているA社の在庫分析手法を共有することで、各社の分析レベルが統一され全体のレベル向上につながります。しかし各社がそれぞれの分析を行うと、成功パターンが業界全体で共有されないまま時間が経過していきます。
FULL KAITENではこの問題を解決するために、バラバラな指標を統一し各社の成功パターンを横展開しやすくしています。業界として分析レベルを上げることで、利益体質な経営の実現を目指しています。









































