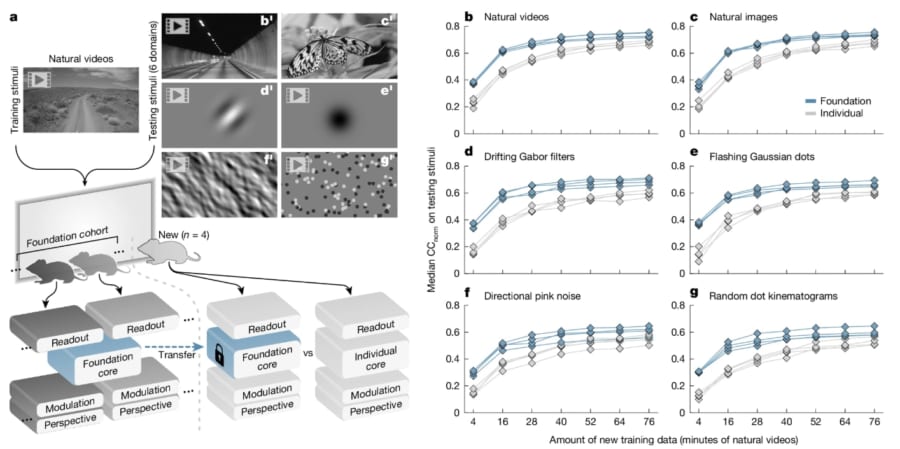
全体の「共通のコア」となる脳の処理モデルを作り上げる流れ / この図は、まず多数のマウスから集めた自然動画データを使って、全体の「共通のコア」となる脳の処理モデルを作り上げる流れを示しています。 この共通のコアは、いわば「基礎地図」のように、複数のマウスで共通する視覚処理のパターンを学習するためのものです。 その後、新たなマウスに対しては、コア部分はそのまま固定し、各マウスに合わせた微調整(視点や行動、出力部分の調整)のみを追加で学習させます。 実験では、わずか4分から最大76分の自然動画データだけで、新しいマウスの視覚野の活動を高い精度で予測できることが確認され、従来の個体ごとに一から学習する方法と比べ大幅なデータ効率の向上が実証されました。 また、図は新たな刺激領域(静止画像や合成パターンなど)においても、このファウンデーションモデルがしっかりと機能することを示し、まるで「共通の地図」を少し補正するだけで未知の地域でも正確な位置が把握できるかのような柔軟性を表しています。/Credit:Eric Y. Wang et al . Nature (2025)