従来はモグラ叩きのように個別対応しかできなかった雑誌のチェック作業も、AIの力を借りることで世界中の雑誌を一気にふるいにかけ、怪しいものを効率よくリストアップすることが可能になります。
AIはどうやって『怪しい雑誌』を見破った?
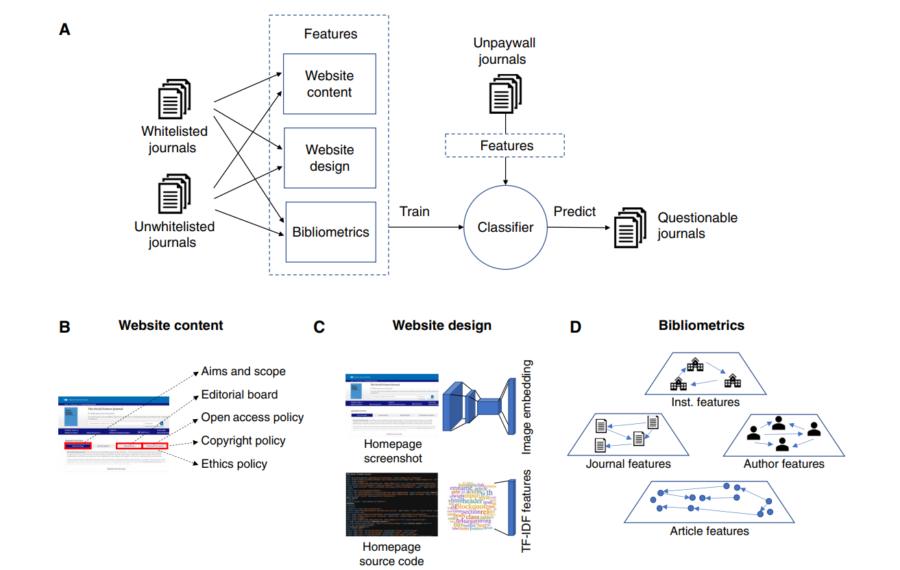 AIはどうやって『怪しい雑誌』を見破った? / スタート地点として、研究チームは「信頼できる雑誌(ホワイトリスト)」と「疑わしい雑誌(ブラックリスト)」の2つのデータセットを用意します。これらは、過去のDOAJ(オープンアクセス雑誌ディレクトリ)の判定をもとに分類されています。AIに学習させるために、この2つのグループからさまざまな特徴データを抽出します。 特徴データは主に3つのグループに分かれています。ひとつは「ウェブサイトの内容」――たとえば雑誌の「目的・範囲」「編集委員の情報」「公開ポリシー」や「倫理規定」など、読者や投稿者向けのテキスト情報です。ふたつめは「ウェブサイトのデザイン」で、これはトップページの画像やHTMLコードなど、その雑誌サイトの“見た目”や“つくり”のパターンです。みっつめは「ビブリオメトリクス」と呼ばれるもので、これは論文の引用関係や著者・機関のデータなど「どんな研究が集まり、どんなふうに引用ネットワークが広がっているか」を数値化した指標です。 このようにして集めた情報をAIに一括で学習させることで、「どの特徴が“怪しさ”につながりやすいか」をAI自身が見抜けるようにしています。図の中には「機械学習モデル」や「分類器(Classifier)」といった言葉が出てきますが、これはAIが“お手本データ”を見て自分でパターンを見つけ、最終的に未知の雑誌に対して「これは怪しいかも」「これは信頼できそう」と判定する仕組みです。全体としては「雑誌データの用意 →さまざまな特徴データの抽出 →AIへの学習・分類モデルの構築 →未知の雑誌データにAIを適用して判定」という流れになっています。Credit:Han Zhuang et al . Science Advances 2025
AIはどうやって『怪しい雑誌』を見破った? / スタート地点として、研究チームは「信頼できる雑誌(ホワイトリスト)」と「疑わしい雑誌(ブラックリスト)」の2つのデータセットを用意します。これらは、過去のDOAJ(オープンアクセス雑誌ディレクトリ)の判定をもとに分類されています。AIに学習させるために、この2つのグループからさまざまな特徴データを抽出します。 特徴データは主に3つのグループに分かれています。ひとつは「ウェブサイトの内容」――たとえば雑誌の「目的・範囲」「編集委員の情報」「公開ポリシー」や「倫理規定」など、読者や投稿者向けのテキスト情報です。ふたつめは「ウェブサイトのデザイン」で、これはトップページの画像やHTMLコードなど、その雑誌サイトの“見た目”や“つくり”のパターンです。みっつめは「ビブリオメトリクス」と呼ばれるもので、これは論文の引用関係や著者・機関のデータなど「どんな研究が集まり、どんなふうに引用ネットワークが広がっているか」を数値化した指標です。 このようにして集めた情報をAIに一括で学習させることで、「どの特徴が“怪しさ”につながりやすいか」をAI自身が見抜けるようにしています。図の中には「機械学習モデル」や「分類器(Classifier)」といった言葉が出てきますが、これはAIが“お手本データ”を見て自分でパターンを見つけ、最終的に未知の雑誌に対して「これは怪しいかも」「これは信頼できそう」と判定する仕組みです。全体としては「雑誌データの用意 →さまざまな特徴データの抽出 →AIへの学習・分類モデルの構築 →未知の雑誌データにAIを適用して判定」という流れになっています。Credit:Han Zhuang et al . Science Advances 2025














































