
今回のOpenAI社から発表された報告書では、モデルの幻覚傾向を定量的に測るテストをいくつか実施しています。
その代表が次の2つの課題です。
1つ目は有名人や歴史上の人物に関する質問で構成された人物課題で、人物についての知識の正確さと架空の経歴や事実を語ってしまわないかを評価します。
2つ目は百科事典的な事実を問う多岐選択の質問4000問からなる一般課題で、各モデルが事実を正しく答えられるか(正答率)と、誤った情報をどれだけ含んだか(幻覚率)を測定します。
評価指標としては、正答率が高いほど事実を正しく答えていることを意味し、幻覚率は低いほど望ましい(幻覚=不正確な情報の混入が少ないこと)と定義されます。
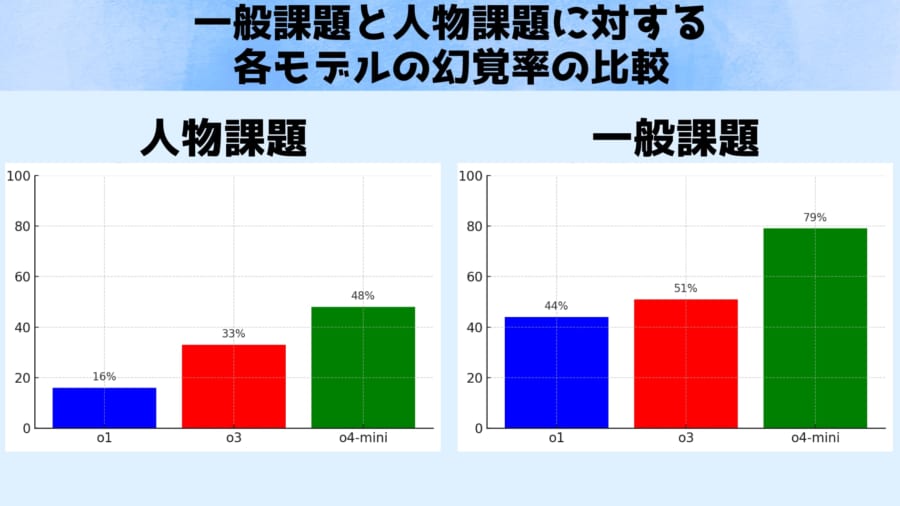
上のグラフは、これらテストの結果を示しています。
人物課題(左)における旧モデルと新モデルの幻覚率を比較しており、最先端モデルのOpenAI o3(赤)は、質問に対し約33%の頻度で幻覚を起こしました。
これは一世代前のモデルo1(青)の約16%と比べてほぼ倍増しています。
さらに小型版モデルのo4-mini(緑)では48%と、回答のほぼ半数が幻覚混じりという深刻な値が報告されました。
一方で人物課題の正答率はo3は59%と、o1の47%よりやや向上していました。
またより一般的な知識を問う一般課題(右)では、幻覚率は51%(o3)対44%(o1)とわずかに新モデルの方が悪化する結果でした。
一般課題の正答率はo3の49%とo1の47%でほぼ同等でした。
しかしo4-miniは一般課題においても正答率20%・幻覚率79%と極めて不安定でした。
これまでの研究でモデルの規模が小さいほど知識が乏しく幻覚を起こしやすいことが知られており、o4-miniの不振は「小型ゆえの限界」と説明できます。
しかし、高性能なはずの大モデルo3までもが先代より幻覚率で劣るという事実には、研究者たちも首をひねっています。































