近年、文章生成AI(チャットボット)の進歩が目覚ましく、医療や法律など高度な領域でも人間並みの回答を出せるとして注目を集めています。
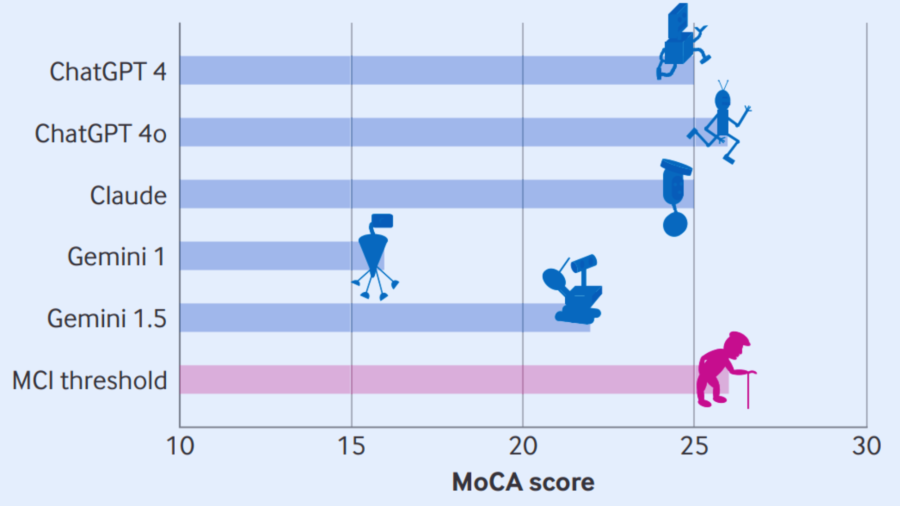
しかし最新の研究によると、これらのAIが人間の認知症を調べるテストを受けると、「古いバージョン」のAIほどスコアが低く、人間でいえば「認知症レベル」と診断されてしまう結果が出たのです。
まるで人間の脳が加齢とともに衰えるかのように、“バージョンが古いAI”ほど視空間認知などの課題を苦手とするという興味深い事実が明らかになりました。
実際にはAIに「脳細胞」があるわけではありません。
それでも、ある種の“バージョンアップ”がされていないAIは、時計を描いたり立体の図形を模写したりするタスクで大きくつまずき、他の症状も含めると「軽度認知障害(MCI)」どころか「重度認知症」に該当するスコアを叩き出したケースもあります。
医療現場での支援役として期待される一方、視空間処理や状況の把握という点では、AIはまだ人間ほど柔軟な理解には至っていないということが、今回のテストを通じて浮き彫りになったわけです。
この結果は、私たちが“AI=何でもできる万能の知性”という先入観を持ってしまうことへの警鐘ともいえるでしょう。
医師や専門家でさえ、高度な医療試験でAIに得点を越されることも珍しくなくなってきました。
しかし、いざ人間の認知機能を測る検査を適用してみると、意外な弱点が炙り出されるのです。
果たして、この“古いAIが認知症テストに落ちる”という事実は、私たちの未来の医療や社会に何を示唆するのでしょうか。
今回のニュースでは、その不思議な現象と背景をわかりやすく解説していきます。
研究内容の詳細は『BMJ』にて公開されました。
目次
- 旧型AIを認知症診断で斬る
- 医学テストで「認知症」と判断されたAI
- なぜ旧型AIは認知症レベルに陥るのか
旧型AIを認知症診断で斬る