ヒトゲノムが本当の意味で全て読み終わりました。
5月27日に
米国立ヒトゲノム研究所(NHGRI)などの国際研究チームによって『bioRxiv』に掲載された論文によれば、ヒトゲノムの端から端に至るまで全てを読むことに、はじめて成功したとのこと。
ヒトゲノム計画はとうの昔に終わったと聞いていましたが、いったいどういうことなのでしょうか?
目次
実は完全に完了していなかったヒトゲノム計画

今から20年前、ヒトゲノム計画を推進する機関とセレラ社(Celera Genomics)の双方から、ヒトゲノムの解読が終了したと発表されました。
しかしこの一般的に流布されている話には裏がありました。
実は「終了」したのは「当時の技術で読み取れる範囲」の解読だったのです。
つまり、できる範囲をやったから「終了」したというわけです。
ヒトゲノムの中には解読を阻む難所が複数存在しており、実に全体の約8%にあたる配列が未決定のままでした。
主な難所となっていたのは、DNA塩基配列が繰り返される部分です。
既存の技術は、DNAを細かい断片に分割してから配列を解読し、後でつなぎ合わせて全体を把握する、というものであったため、「AGAGAGAG」のように同じ文字の繰り返しが延々と続く部分では正確に読み取れなかったのです。
しかし今回、研究者たちはオックスフォード・ナノポア社が開発した一度に100万文字が読める技術で繰り返し配列を力技で越えると同時に、パックビオ社が開発したDNAにあてたレーザーの反射から配列を直接的に読み込んでいく超高精度な方法で検証していきました。
結果、本当の意味でヒトゲノムの全ての配列を端から端まで解読することに成功します。
最新の方法で読まれたヒトゲノムにはタンパク質をコードする部分は1万9969個となります。
これは2019年の研究で更新された数(1万9890個)よりも79個多くなります。
どうやらヒトゲノムのタンパク質コード領域は2万個にギリギリ満たない数なようです。
また興味深い点として、今回の研究で解読対象となった細胞は、染色体の数も通常の半分にあたる、23本しかないものが選ばれました。
研究者たちは、いったいどんな細胞のゲノムを読んだのでしょうか?
解読されたのは生きている人間のゲノムではない
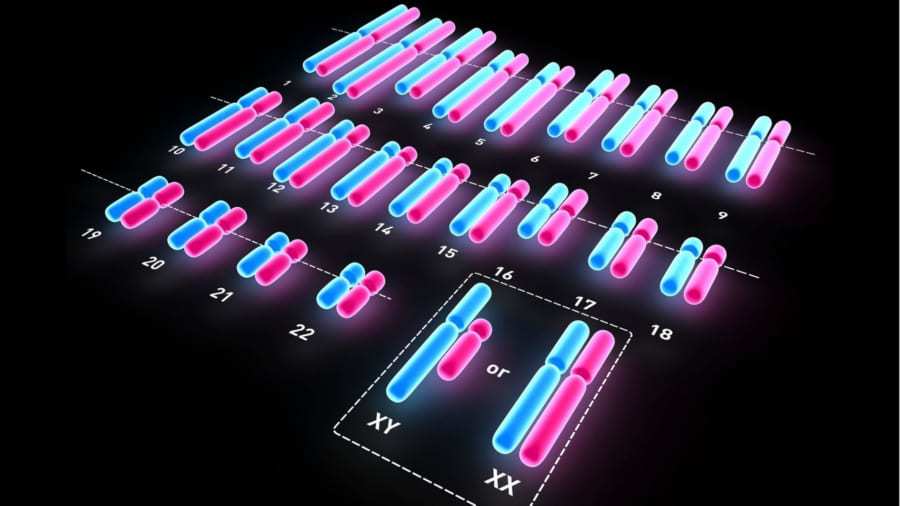
これまでのヒトゲノム解読において使われてきたのは、特定のヒトの体細胞でした。
しかしヒトのゲノムは父親からもらったセットと母親からもらったセットが存在しており、対策せずに解読した場合、得られる配列情報は父親と母親のものが交じり合ったモザイク状のものになってしまいます。
そこで今回、研究者たちは解読対象に胞状奇胎の細胞を使うことにしました。
胞状奇胎は何らかの原因で核が抜けてしまった卵子に精子が受精することで発生する異常妊娠であり、ヒトの形を留めないばかりか、細胞には精子が運んでいた23本の染色体しか含まれていません。
ですがこの胞状奇胎の特性は完璧な配列決定には望ましいものでした。
胞状奇胎の細胞には精子(父親)由来の染色体セットしか存在しないために、解読結果がモザイク状にならずにすむからです。













































