目次
「会話から行動する」ロボットの開発を進めるGoogle
・PaLMをロボットに実装する
・Transformerとロボット工学の合流点「RT-1」
ルール違反についても学習したDeepMindの「Sparrow」
「会話から行動する」ロボットの開発を進めるGoogle
Googleが開発する会話AIとして知られているのは、LaMDAです。同モデルに関してはユーザ参加型テスト「AI Test Kitchen」がフェーズ2まで進み、同モデルをベースに開発されたAIライティングツール「Wordcraft」を使ったワークショップも開催されました(※注釈2)。
近年Googleは、自然言語処理とロボット工学を統合する研究も推進しています。以下では、2022年に大きく前進した「会話から行動するロボット」に関する同社の取り組みを紹介します。
(※注釈2)AI Test Kitchenフェーズ2とWordcraftの詳細は、AINOW特集記事『Google開催のAI特化型イベント「AI@ ’22」レポート』の「画像生成に対応するAI Test Kitchen Season 2」と「作家を集めて創作活動を実験したWordcraft」を参照のこと。
PaLMをロボットに実装する
産業用ロボットに代表される従来のロボットは、事前にプログラミングされたタスクだけを実行する柔軟性に欠けたものでした。近年の自然言語処理の発展によって、従来より人間と自然に会話できるロボットが登場しましたが、こうしたロボットが実行するのは言わば「おしゃべり」だけです。ロボットに真に求められるのは、限られたタスクや自然なおしゃべりにとどまらず、人間との会話を理解したうえでさまざまなタスクを実行できる汎用的な言語理解能力と行為遂行能力だと言えます。
2022年8月15日、Googleは汎用的なロボット開発の第1歩となるプロトタイプロボット「PaLM-SayCan」を発表しました。このロボットは、例えば「おやつをキッチンから取って来て」という人間の言葉を理解したうえで、実際にその言葉の内容を実行します。
PaLM-SayCanは、その名称が示す通り、Googleが開発した大規模言語モデルPaLM(※注釈3)が実装されています。同モデルを実装したことによって、同ロボットは言葉とその内容を満たすタスクの対応関係を理解できるようになったのです。同ロボットは人間とタスクを介して会話している、とも言えます。
GoogleはPaLM-SayCanの汎用性を拡張する研究を続け、2022年11月2日には言語モデルのコード生成能力に着目して、制御プログラミングを自己生成するロボットを発表しました。また、2022年12月1日には、言語による行動表現とロボットの動作を対応させたデータセットを公開しました。
(※注釈3)PaLMの詳細は、AINOW特集記事『Google I/O 2022で発表された最新自然言語処理技術まとめ』の「世界最大サイズの言語モデル「PaLM」」を参照のこと。
Transformerとロボット工学の合流点「RT-1」
2022年12月13日、GoogleはPaLM-SayCanから始まるロボット研究に一区切りをつけるような研究成果を発表しました。その成果とは、Transformerをベースに構築されたロボット開発プラットフォーム「RT-1(Robotics Transformer-1)」です。
近年の自然言語処理研究は、周知のようにTransformerの登場によって大きく発展しました。この技術は、自然言語処理のみならず画像処理にも応用されるようになって、2022年に大きな話題となった画像生成AIにも活用されています。
Google研究チームはTransformerの汎用性と拡張性に着目して、この技術をロボット開発に応用しました。具体的には、ロボットに搭載したカメラが撮影した画像とタスクを記述した言語表現を入力、ロボットの動作を出力として、こうした入力と出力をともにトークン化してTransformerで処理可能としたのです。
以上のようにしてTransformerを活用することによって、今後のロボット開発が大きく発展することが期待できます。というのも、2017年に発表された同技術によって実現した自然言語処理の進化と同等の進化がロボット開発にも起こるかも知れないからです。
ルール違反についても学習したDeepMindの「Sparrow」
DeepMindは、2022年9月22日により安全に人間と会話できることを目指して開発した会話AI「Sparrow」を発表しています。このAIの開発には、OpenAIのChatGPTで使われたような人間の評価を組み込んだ強化学習が実施されました。具体的には、任意の質問に対する回答を複数用意したうえで、人間の評価者にもっとも納得のいく回答を選んでもらいます。このようにして好ましい回答を収集してうえで、好ましい回答を出力するように会話AIを訓練したのです。好ましい回答を収集する際には、インターネットから取得した情報を含む回答とそうでない回答の両方を用意したうえで、どのような場合に証拠を必要とするのか、ということも考察できるようにしました。
Sparrowの開発では、どのような場合に暴力的な発言を生成してしまうかといった倫理的ルールに違反する事例も収集しました。そして、同モデルに対して違反事例を回避するようにも訓練しました。つまり、倫理的ルールを簡単に破らないような学習も実施したのです。
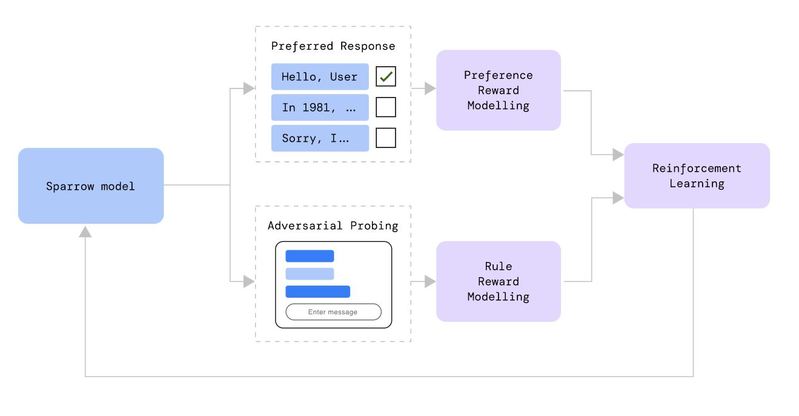
以上のように開発したSparrowをテストした結果、事実と関係のある質問に対して、78%の確率で証拠を示したうえで説得力のある回答を生成できました。また、同モデルを騙して倫理的ルールを破るようにしむけるテストも実施したところ、実際にルールを破った事例は8%に留まりました。このルール違反率は、ベースラインモデルに同様のテストをしたところ3倍の確率でルール違反したことを考慮すると、確かな進歩だと言えます。
なお、Sparrowを論じた論文では今後の課題としてより説得力のある回答の生成を挙げています。人間は強い信念を持っている時、その信念と矛盾した証拠があるにもかかわらず、信念を修正できないことがあります。こうした誤りを含む強固な信念を正すような回答を生成することが、将来の会話AIで実現すべき目標として掲げられています。
(※注釈4)TIME誌電子版が2023年1月12日に公開したDeepMindのCEOであるDemis Hassabis氏のインタビュー記事のよると、同社は2023年のある時期にSparrowのプライベートベータ版をリリースすることを検討している。同モデルにはChatGPTにはない「情報源の引用」機能が実装され、その機能は強化学習によって開発される。
なお、OpenAIは2021年12月16日、質問に対する回答の根拠としてウェブページを引用する「WebGPT」を発表している。同モデルはGPT-3よりもっともらしい回答を生成するが、間違うこともある。しかしながら、根拠となるウェブページを引用することで誤った回答を「権威化する」するリスクがあり、改善の余地があると述べている。












































